108年:(醫檢)檢驗(2)
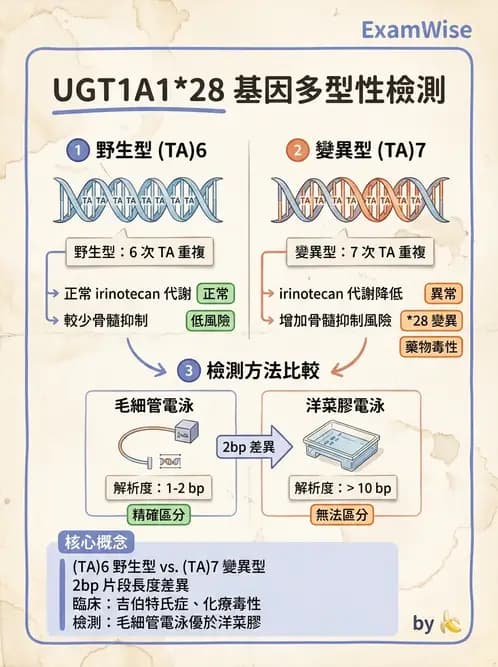
最常見的 UGT1A1 基因多型性是啟動子區域的( TA )重複序列數目的變化,下列敘述何者錯誤?
A可以使用桑格定序法檢測
B多數個體在此位置的 TA 重複序列為六個
CUGT1A1*28 變異型之 TA 重複序列為七個
D利用 ISSR-PCR (inter simple sequence repeat-PCR )法對 UGT1A1*28 變異型檢測的反應產物,可利用洋菜膠 電泳判斷其 PCR 產物大小
詳細解析
本題觀念:
UGT1A1 基因啟動子 TA 重複序列多型性(特別是 UGT1A1*28),以及各種偵測方法的原理與適用性。
選項分析
(A) 可以使用桑格定序法(Sanger sequencing)檢測 ✅ Sanger 定序法可直接讀取 UGT1A1 啟動子區域的核苷酸序列,清楚辨識 TA 重複數目,是有效的檢測方法之一,文獻中亦有使用記載。
(B) 多數個體在此位置的 TA 重複序列為六個 ✅ 野生型(wild-type)UGT1A1 啟動子含有 6 個 TA 重複,即 A(TA)TAA,此為最常見的基因型,在各族群中均以 (TA) 最為普遍。
(C) UGT1A128 變異型之 TA 重複序列為七個 ✅ UGT1A128(rs8175347)為啟動子 TATA box 區域含有 7 個 TA 重複,即 A(TA)TAA,會降低 UGT1A1 基因轉錄效率,導致膽紅素葡醣醛酸化酶(UGT1A1)表現量下降,與吉伯特氏症候群(Gilbert syndrome)及 irinotecan 藥物毒性增加有關。
(D) 利用 ISSR-PCR(inter simple sequence repeat-PCR)法對 UGT1A1*28 變異型檢測的反應產物,可利用洋菜膠電泳判斷其 PCR 產物大小 ❌(答
...(解析預覽)...
升級 VIP 解鎖圖文解析